keywords
Huaxin International Investigation (HII)Investigation Services in China
Over the past few years, cloud computing is maturing and has revolutionized the methods by which digital information is stored, transmitted, and processed. Cloud computing is not just a hyped model but embraced by Information Technology giants such as Apple, Amazon, Microsoft, Google, Oracle, IBM, HP, and others. Cloud computing has major concerns due to its architecture despite the technological innovations that have made it a feasible solution. It is difficult to fix the responsibility of a security breach in cloud due to the complex structure of the cloud services. In last decade, cloud computing security seems to be the most frequently surveyed topic among others by leading organizations such as IDC (International Data Corporation) and Gartner.
Recent attacks on cloud such as Sony Email hack, Apple iCloud hack, etc., proved the vulnerability in cloud platforms and require immediate attention for digital forensics in cloud computing environment. Cloud Security Alliance (CSA) conducted a survey related to the issues of forensic investigation in the cloud computing environments [1]. The survey document summarizes the international standards for cloud forensics, and integration of the requirements of cloud forensic into service level agreements (SLAs). In June 2014, NIST (National Institute of Standards and Technology) established a working group called NIST Cloud Computing Forensic Science Working Group (NCC FSWG) to research challenges in performing digital forensics in cloud computing platform. This group aims to provide standards and technology research in the field of cloud forensics that cannot be handled with current technology and methods [2]. The NIST document lists all the challenges along with preliminary analysis of each challenge by providing associated literature and relationship to the five essential characteristics of cloud. Our work focuses on some of the issues and/or challenges pointed out in the above two documents [1, 2].
The remaining part of the paper is organized as follows: In Sect. 1 we discuss an introduction cloud forensics. Section 2 provides the details of literature review. Section 3 emphasizes on the digital forensics architecture for cloud computing. Section 4 lists the methods of evidence source identification, segregation and acquisition. Section 5 describes the techniques for partial analysis of evidence related to a user account in private cloud. Finally we conclude the work and discuss future enhancements in Sect. 6.
1.1 Cloud Forensics
For traditional digital forensics, there are well-known commercial and open source tools available for performing forensic analysis [3, 4, 5, 6, 7, 8]. These tools may help in performing forensics in virtual environment (virtual disk forensics) to some extent, but may fail to complete the forensic investigation process (i.e., from evidence identification to reporting) in the cloud; particularly cloud log analysis. Ruan et al., have conducted a survey on “Cloud Forensics and Critical Criteria for Cloud Forensic Capability” in 2011 to define cloud forensics, to identify cloud forensics challenges, to find research directions etc. as the major issues for the survey. The majority of the experts involved in the survey agreed on the definition “Cloud forensics is a subset of network forensics” [9]. Network forensics deals with forensic investigations of computer networks. Also, cloud forensics was defined by other researchers such as Shams et al. in 2013 as “the application of computer forensic principles and procedures in a cloud computing environment” [10]. The cloud deployment model under investigation (private, community, hybrid, or public) will define the way in which digital forensic investigation will be carried out. The work presented in this paper is restricted to IaaS model of private or public cloud infrastructure.
2 Literature Review
Dykstra et al. have used existing tools like Encase Enterprise, FTK, Fastdump, Memoryze, and FTK Imager to acquire forensic evidence from public cloud over the Internet. The aim of their research was to measure the effectiveness and accuracy of the traditional digital forensic tools on an entirely different environment like cloud. Their experiment showed that trust is required at many layers to acquire forensic evidence [11]. Also, they have implemented user-driven forensic capabilities using management plane of a private cloud platform called OpenStack [12]. The solution is capable of collecting virtual disks, guest firewall logs and API logs through the management plane of OpenStack [13]. Their emphasis was on data collection and segregation of log data in data centers using OpenStack as cloud platform. Hence, their solution is not independent of OpenStack platform and till date it has not been added to the public distribution (the latest stable version of OpenStack is Kilo released on 30th April 2015).
To our knowledge, there is no digital forensic solution (or toolkit) that can be used in the cloud platforms to collect the cloud data, to segregate the multi-tenant data, to perform the partial analysis on the collected data to minimize the overall processing time of cloud evidence. Inspired with the work of Dykstra and Sherman, we have contributed in designing the digital forensic architecture for cloud; implementing modules for data segregation and collection; implementing modules for partial analysis of evidence within (virtual hard disk, physical memory of a VM) and outside (cloud logs) of a virtual environment called cloud.
3 Digital Forensics Architecture for Cloud Computing
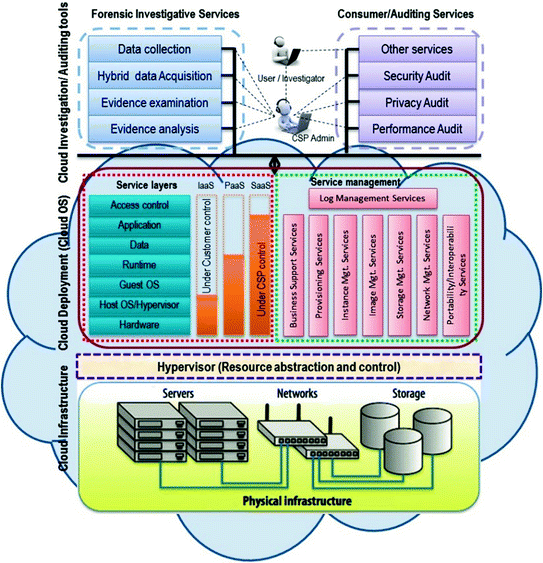
Digital forensic architecture for cloud computing systems
Cloud provider may have external auditing services for auditing security, auditing privacy, and auditing performance. Our goal is to provide forensic investigative services for data collection, hybrid data acquisition, and partial evidence analysis. As shown in the figure, admin of CSP (Cloud Service Provider) can make use of Forensic Investigative Services directly whereas cloud user and/or investigator have to depend on the cloud admin. The suggested digital forensic architecture for cloud computing systems is generic and can be used by any cloud deployment model.
3.1 Cloud Deployment (Cloud OS)
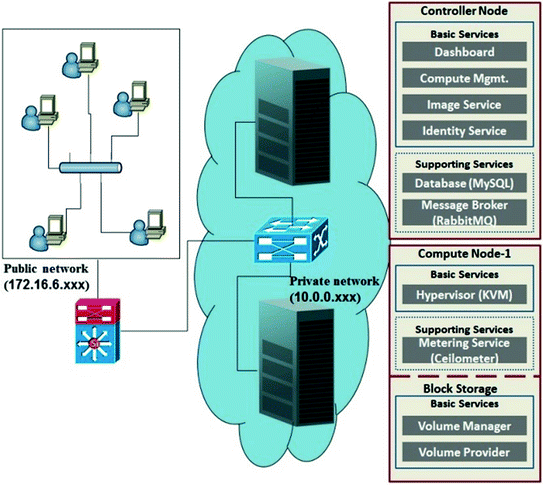
Conceptual architecture of the private cloud IaaS
4 Digital Evidence Source Identification, Segregation and Acquisition
4.1 Identification of Evidence
The virtual machine is as good as a physical machine and creates lots of data in the cloud for its activity and management. The data created by a virtual machine includes virtual hard disk, physical memory of the VM, and logs. Virtual hard disk formats that different cloud provider may support include .qcou2, .vhd, .vdi, .vmdk, .img, etc. Every cloud provider may have their own mechanism for service logs (activity maintenance information) and hence there is no interoperability on log formats among cloud providers. The virtual hard disk file will be available in the compute node where the corresponding virtual machine runs. Cloud logs will be spread across controller and compute nodes.
4.2 Evidence Segregation
Cloud computing platform is a multi-tenant environment where end users share cloud resources and log files that store cloud computing services activity. These log files cannot be provided to the investigator and/or cloud user for forensic activity due to the privacy issues of other users in the same environment. Dykstra and Sherman [12] have suggested a tree based data structure called “hash tree” to store API logs and firewall logs. Since we have not modified any of the OpenStack service modules, we have implemented a different approach of logging known as “shared table” database. In this approach, a script runs at the host server where the different services of the OpenStack are installed (for examples “nova service”). This script mines the data from all the log files and creates a database table. This database table contains the data of multi-tenants and the key to uniquely identify a record is “Instance ID” which is unique to a virtual machine. Now, cloud user and/or investigator with the help of cloud administrator can query the database for any specific information from a remote system as explained in Sect. 4.3.
4.3 Evidence Acquisition
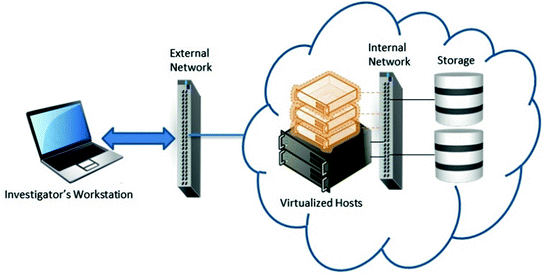
Remote data acquisition in private cloud data center
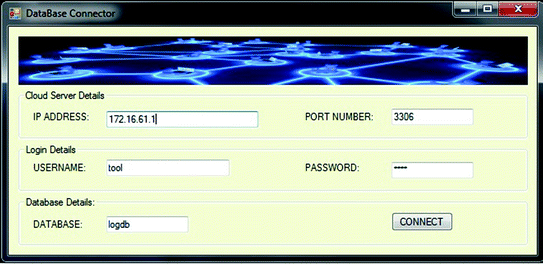
Connecting to cloud hosting server that stores the shared table database
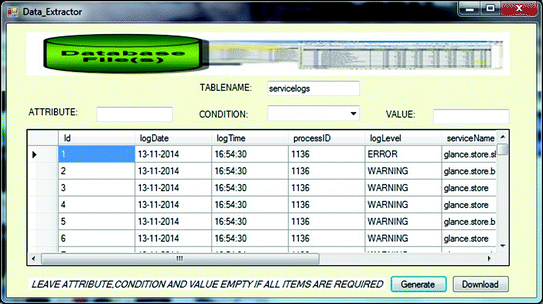
Shared table with different attribute information
5 Partial Analysis (or Examination) of Evidence
The evidence examination and analysis approaches of traditional digital forensics cannot be directly applicable to cloud data due to virtualization and multi-tenancy. There is a requirement of “digital forensic triage” to enable cybercrime investigator to understand whether the case is worthy enough for investigation. Digital forensic triage is a technique used in the selective data acquisition and analysis to minimize the processing time of digital evidence. We now present the methods of partial analysis (also called evidence examination) required for virtual machine data.
5.1 Within the Virtual Machine
Using the examination phase at the scene of crime at different parts of evidence, we provide the investigator with enough knowledge base of the file system metadata, content of logs (for example content of registry files in Windows), and internals of physical memory. With this knowledge base, the investigator will have in-depth understanding of the case under investigation and may save a considerable amount of valuable time which can be efficiently utilized for further analysis.
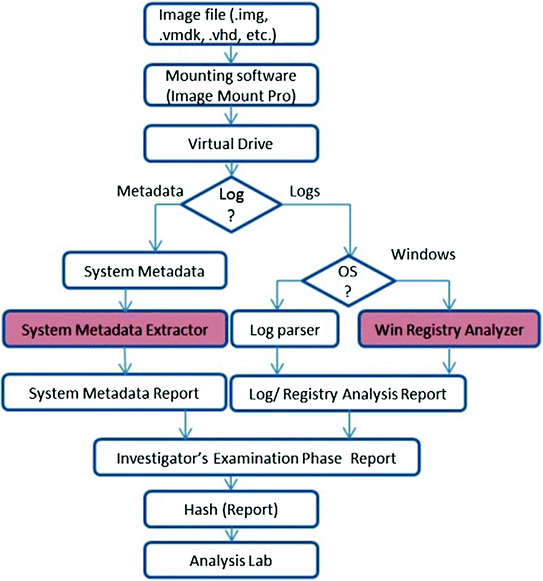
Virtual disk examination process

File system metadata extractor

Windows registry analyzer
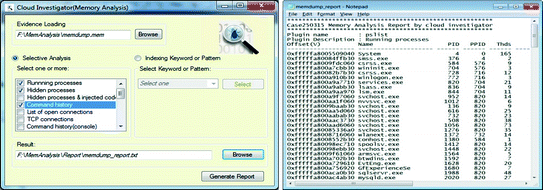
Selective memory analysis

Multiple keywords search (indexing)

Multiple pattern search (indexing)
6 Conclusion and Future Work
Adaptation of digital forensic techniques to the cloud environment is challenging in many ways. Cloud as a business model presents a range of new challenges to digital forensic investigators due to its unique characteristics. It is necessary that the forensic investigators and/or researchers adapt the existing traditional digital forensic practices and develop new forensic models, which would enable the investigators to perform digital forensics in cloud.
In our paper, we have designed a digital forensic architecture for the cloud computing systems which may be useful to the digital forensic community for designing and developing new forensic tools in the area of cloud forensic; we have framed ways in which we can do digital evidence source identification, segregation and acquisition of evidentiary data. In addition, we have formulated methods for examination of evidence within (virtual hard disk, physical memory of a VM) and outside (logs) of a virtual environment called cloud. The approach we suggested for segregation (log data) will facilitate a software client to support collection of cloud evidentiary data (forensic artifacts) without disrupting other tenants. To minimize the processing time of digital evidence, we proposed solutions for the initial forensic examination of virtual machine data (virtual hard disk, physical memory of a VM) in the places where the digital evidence artifacts are most likely to be present. As understanding the case under investigation is done in a better way, it saves considerable time, which can be efficiently utilized for further analysis. Hence, the investigation process may take less time than actually required. The mechanisms we developed were tested in the OpenStack cloud environment. In future, we plan to test the solutions in other platforms.